
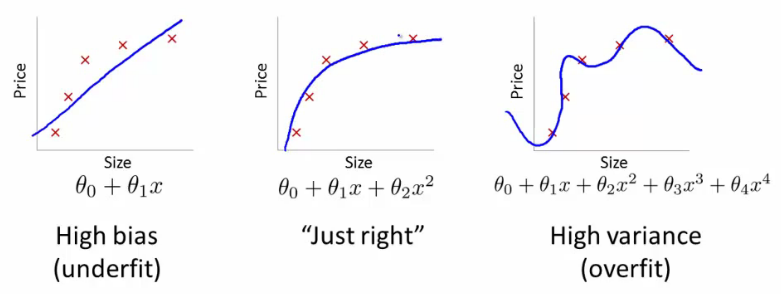
So you built a Machine Learning model?
You have been working on a Machine Learning project. You collected data from various sources, built your model and got some preliminary results. You notice you are getting about 80% accuracy on your test set which is less than what you desire. Now what? How do you improve the model?
Should you get more data? Build a more complex model? Increase or decrease regularization? Add or remove features? Run more iterations of gradient descent? Maybe try all of them?
Recently I got this question from a friend, who said it seemed that improving models is just hit and trial. This prompted me to write this post on how to make an informed decision about what should you work on first.
Bias and Variance
To build a more accurate model, we first need to learn what are the different sources of error in our model.
Bias: The error due to bias is taken as the difference between the expected (or average) prediction of our model and the correct value which we are trying to predict.
Variance: The error due to variance is taken as the variability of a model prediction for a given data point.
Mathematical definition
We are trying to predict \(Y\) and our input is \(X\). Let’s assume there is a relationship relating one to the other such as \(Y = f(X) + \epsilon\) where the error term \(\epsilon\) is normally distributed with a mean of zero like so \(\epsilon \sim \mathcal{N}(0,\sigma_\epsilon)\).
We may estimate a model \(\hat{f}(X)\) of \(f(X)\) using linear regressions or another modeling technique. Then, the expected squared prediction error at a point \(x\) is:
\[Err(x) = E\left[(Y-\hat{f}(x))^2\right]\]The error can be split into bias and variance components:
\[Err(x) = \left(E[\hat{f}(x)]-f(x)\right)^2 + E\left[\left(\hat{f}(x)-E[\hat{f}(x)]\right)^2\right] +\sigma_e^2\] \[Err(x) = \mathrm{Bias}^2 + \mathrm{Variance} + \mathrm{Irreducible\ Error}\]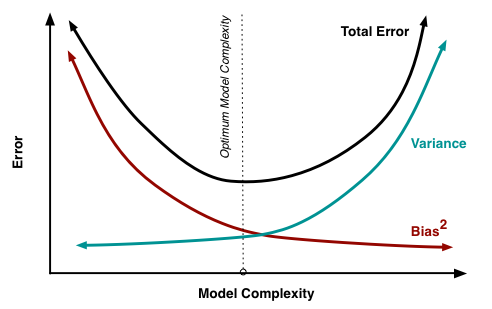
The irreducible error is the noise term in the true relationship that cannot be fundamentally reduced by any model. Given the true model and infinite data to calibrate it, we should be able to reduce both the bias and variance terms to 0. However, in a world with imperfect models and finite data, there is a tradeoff between minimizing the bias and minimizing the variance.
What are Learning Curves?
Now we know about Bias and Variance and the tradeoff between the two, but the problem of how to improve our model still remains. What is our model suffering from - high bias or high variance? To answer this we need to plot Learning curves for the model.
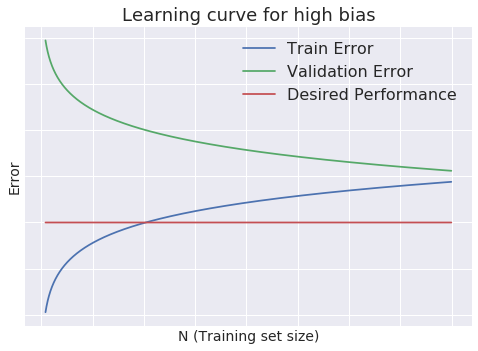
High Bias
- Low training set size: \(J_{train}(\Theta)\) will be low and \(J_{CV}(\Theta)\) will be high
- Large training set size: \(J_{train}(\Theta)\) and \(J_{CV}(\Theta)\) will be high with \(J_{train}(\Theta) \approx J_{CV}(\Theta)\)
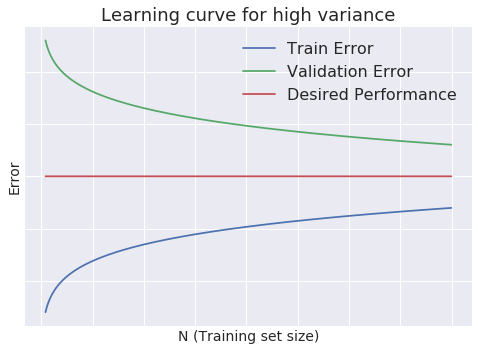
High Variance
- Low training set size: causes \(J_{train}(\Theta)\) will be low and \(J_{CV}(\Theta)\) will be high
- Large training set size: \(J_{train}(\Theta)\) increases with training set size and \(J_{CV}(\Theta)\) continues to decrease without leveling off. \(J_{train}(\Theta) < J_{CV}(\Theta)\) but the difference between them remains significant
What to do next?
We have figured out if we have a bias problem or a variance one. We can make an informed choice about what to work on next.
High Bias
- Try more complex features, polynomial terms or adding more nodes
- Decreasing the regularization parameter \(\lambda\)
High Variance
- Collecting more training data as that will help the model generalize better
- Reducing the feature set size
- Increasing the regularization parameter \(\lambda\)

What if I have an ML pipeline?
As most machine learning systems are built using a chain of models. It is fairly common to have a scenario where you have an ML pipeline and want to figure out which part to work on next? Ceiling Analysis can be useful here.
For Ceiling Analysis plug in a perfect version for each component of the pipeline one at a time and then measure how much improvement do we see in the complete pipeline. This can give us a sense of working on which component gives us the highest bang for the buck.

Let’s say in the above character detection pipeline you observe that a perfect character segmentation system gives a 1% boost to the overall system while a perfect character recognition system will provide a 7% boost. So we should focus on improving the recognition system much more so than the segmentation model.